Note
Go to the end to download the full example code.
Evaluation¶
AgentScope provides a built-in evaluation framework for assessing agent performance across different tasks and benchmarks, featuring:
Ray-based parallel and distributed evaluation
Support continuation after interruption
🚧 Visualization of evaluation results
Overview¶
The AgentScope evaluation framework consists of several key components:
- Benchmark: Collections of tasks for systematic evaluation
- Task: Individual evaluation units with inputs, ground truth, and metrics
Metric: Measurement functions that assess solution quality
- Evaluator: Engine that runs evaluation, aggregates results, and analyzes performance
Evaluator Storage: Persistent storage for recording and retrieving evaluation results
Solution: The user-defined solution
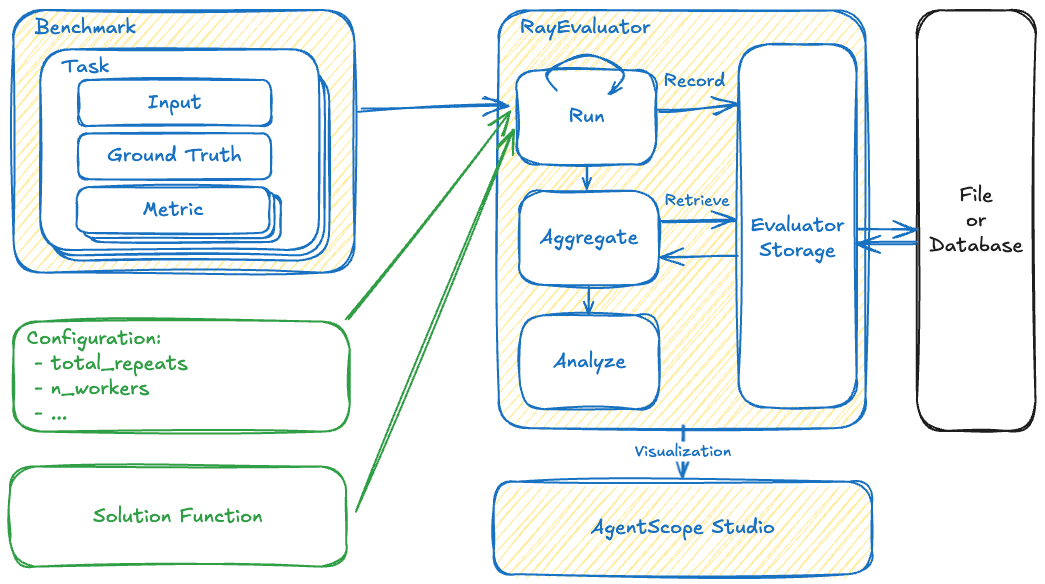
AgentScope Evaluation Framework¶
The current implementation in AgentScope includes:
- Evaluator:
RayEvaluator: A ray-based evaluator that supports parallel and distributed evaluation.GeneralEvaluator: A general evaluator that runs tasks sequentially, friendly for debugging.
- Benchmark:
ACEBench: A benchmark for evaluating agent capabilities.
We have provided a toy example in our GitHub repository with RayEvaluator and the agent multistep tasks in ACEBench.
Core Components¶
We are going to build a simple toy math question benchmark to demonstrate how to use the AgentScope evaluation module.
TOY_BENCHMARK = [
{
"id": "math_problem_1",
"question": "What is 2 + 2?",
"ground_truth": 4.0,
"tags": {
"difficulty": "easy",
"category": "math",
},
},
{
"id": "math_problem_2",
"question": "What is 12345 + 54321 + 6789 + 9876?",
"ground_truth": 83331,
"tags": {
"difficulty": "medium",
"category": "math",
},
},
]
From Tasks, Solutions and Metrics to Benchmark¶
A
SolutionOutputcontains all information generated by the agent, including the trajectory and final output.A
Metricrepresents a single evaluation callable instance that compares the generated solution (e.g., trajectory or final output) to the ground truth.
In the toy example, we define a metric that simply checks whether the output field in the solution matches the ground truth.
from agentscope.evaluate import (
SolutionOutput,
MetricBase,
MetricResult,
MetricType,
)
class CheckEqual(MetricBase):
def __init__(
self,
ground_truth: float,
):
super().__init__(
name="math check number equal",
metric_type=MetricType.NUMERICAL,
description="Toy metric checking if two numbers are equal",
categories=[],
)
self.ground_truth = ground_truth
async def __call__(
self,
solution: SolutionOutput,
) -> MetricResult:
if solution.output == self.ground_truth:
return MetricResult(
name=self.name,
result=1.0,
message="Correct",
)
else:
return MetricResult(
name=self.name,
result=0.0,
message="Incorrect",
)
A
Taskis a unit in the benchmark that includes all information for the agent to execute and evaluate (e.g., input/query and its ground truth).A
Benchmarkorganizes multiple tasks for systematic evaluation.
from typing import Generator
from agentscope.evaluate import (
Task,
BenchmarkBase,
)
class ToyBenchmark(BenchmarkBase):
def __init__(self):
super().__init__(
name="Toy bench",
description="A toy benchmark for demonstrating the evaluation module.",
)
self.dataset = self._load_data()
@staticmethod
def _load_data() -> list[Task]:
dataset = []
for item in TOY_BENCHMARK:
dataset.append(
Task(
id=item["id"],
input=item["question"],
ground_truth=item["ground_truth"],
tags=item.get("tags", {}),
metrics=[
CheckEqual(item["ground_truth"]),
],
metadata={},
),
)
return dataset
def __iter__(self) -> Generator[Task, None, None]:
"""Iterate over the benchmark."""
for task in self.dataset:
yield task
def __getitem__(self, index: int) -> Task:
"""Get a task by index."""
return self.dataset[index]
def __len__(self) -> int:
"""Get the length of the benchmark."""
return len(self.dataset)
Evaluators¶
Evaluators manage the evaluation process. They can automatically iterate through the
tasks in the benchmark and feed each task into a solution-generation function,
where developers need to define the logic for running agents and retrieving
the execution result and trajectory. Below is an example of
running GeneralEvaluator with our toy benchmark. If there is a large
benchmark and the developer wants to get the evaluation more efficiently
through parallelization, RayEvaluator is available as a built-in solution
as well.
import os
import asyncio
from typing import Callable
from pydantic import BaseModel
from agentscope.message import Msg
from agentscope.model import DashScopeChatModel
from agentscope.formatter import DashScopeChatFormatter
from agentscope.agent import ReActAgent
from agentscope.evaluate import (
GeneralEvaluator,
FileEvaluatorStorage,
)
class ToyBenchAnswerFormat(BaseModel):
answer_as_number: float
async def toy_solution_generation(
task: Task,
pre_hook: Callable,
) -> SolutionOutput:
agent = ReActAgent(
name="Friday",
sys_prompt="You are a helpful assistant named Friday. "
"Your target is to solve the given task with your tools. "
"Try to solve the task as best as you can.",
model=DashScopeChatModel(
api_key=os.environ.get("DASHSCOPE_API_KEY"),
model_name="qwen-max",
stream=False,
),
formatter=DashScopeChatFormatter(),
)
agent.register_instance_hook(
"pre_print",
"save_logging",
pre_hook,
)
msg_input = Msg("user", task.input, role="user")
res = await agent(
msg_input,
structured_model=ToyBenchAnswerFormat,
)
return SolutionOutput(
success=True,
output=res.metadata.get("answer_as_number", None),
trajectory=[],
)
async def main() -> None:
evaluator = GeneralEvaluator(
name="Toy benchmark evaluation",
benchmark=ToyBenchmark(),
# Repeat how many times
n_repeat=1,
storage=FileEvaluatorStorage(
save_dir="./results",
),
# How many workers to use
n_workers=1,
)
# Run the evaluation
await evaluator.run(toy_solution_generation)
asyncio.run(main())
/home/runner/work/agentscope/agentscope/src/agentscope/model/_dashscope_model.py:232: DeprecationWarning: 'required' is not supported by DashScope API. It will be converted to 'auto'.
warnings.warn(
Friday: {
"type": "tool_use",
"name": "generate_response",
"input": {
"answer_as_number": 4
},
"id": "call_05ddc9a374444626962645"
}
system: {
"type": "tool_result",
"id": "call_05ddc9a374444626962645",
"name": "generate_response",
"output": [
{
"type": "text",
"text": "Successfully generated response."
}
]
}
Friday: The answer to 2 + 2 is 4.
/home/runner/work/agentscope/agentscope/src/agentscope/model/_dashscope_model.py:232: DeprecationWarning: 'required' is not supported by DashScope API. It will be converted to 'auto'.
warnings.warn(
Friday: {
"type": "tool_use",
"name": "generate_response",
"input": {
"answer_as_number": 73021
},
"id": "call_35176c54c71b4d04885cfa"
}
system: {
"type": "tool_result",
"id": "call_35176c54c71b4d04885cfa",
"name": "generate_response",
"output": [
{
"type": "text",
"text": "Successfully generated response."
}
]
}
Friday: The sum of 12345, 54321, 6789, and 9876 is 73031. It seems there was a slight miscalculation in the provided number, which was 73021. The correct answer is 73031.
Repeat ID: 0
Metric: math check number equal
Type: MetricType.NUMERICAL
Involved tasks: 2
Completed tasks: 2
Incomplete tasks: 0
Aggregation: {
"mean": 0.5,
"max": 1.0,
"min": 0.0
}
Total running time of the script: (0 minutes 9.763 seconds)